Gen AI for Opera: Democratizing AI Model Creation
No-code custom AI model development
Vision
Enable users to independently build AI models, reducing reliance on internal teams and accelerating innovation.
Problem:
Customers needed a way to build language models without requiring technical expertise.
Business need:
Expand self-service capabilities for customers and reduce reliance on internal teams.
My role:
Led end-to-end design from concept to launch.
Outcome:
Beta launch attracted two new customers.
Learning:
Strategic, hands-on guidance proved essential for successful adoption.
What is Opera?
Opera is Cresta's no-code platform that enables contact center leaders to automate coaching and monitor compliance — without needing AI expertise.
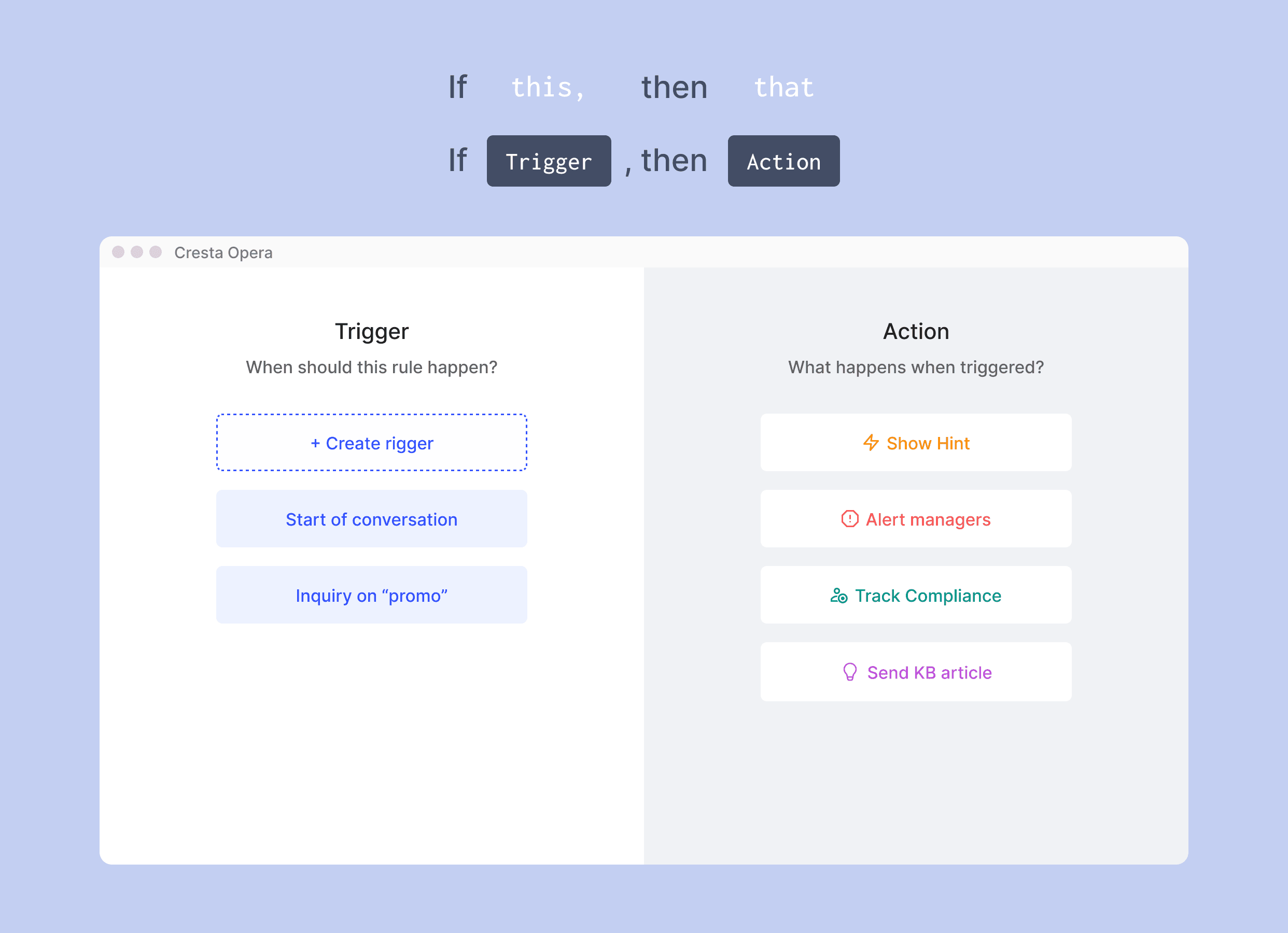
Users can create custom rules in an "if this, then that" format for simple scenarios, complementing Cresta's AI models that handle complex interactions.

For example, if a customer inquires about an upgrade, agents should receive a reminder on the temporary promotion the company is running for the month of July. Then as a Cresta Opera user, I can go to Opera and create this rule.
Problem 1: Low accuracy
Opera primarily used a keyword builder to define triggers. Keywords were easy to use at first but eventually proved limited in practice.
It was difficult to capture triggering moments holistically using just a few words.
Problem 2: Long wait
When users needed higher quality AI models, they were dependent on Cresta's AI Delivery team. However, the backlog of custom developments and changes created significant delays, leaving users waiting long periods for improvements.
But how does LLM help?
Using Generative AI, users can make customizations without a long wait or accuracy problems!


So what is the general flow?
Here are the three phases users will go through to define the trigger using generative AI. This doesn’t mean the entire flow is limited to just three steps… (although it did in the first iteration 🙃)

First iteration
In step 1, the user defines the moment they'd like to capture.
In step 2, the user marks whether the phrases are true or false examples of the moment they'd like to define.
Then lastly in step 3, the user reviews model's predictions.
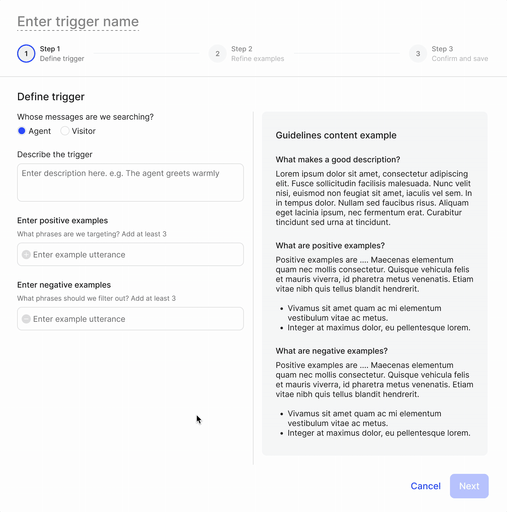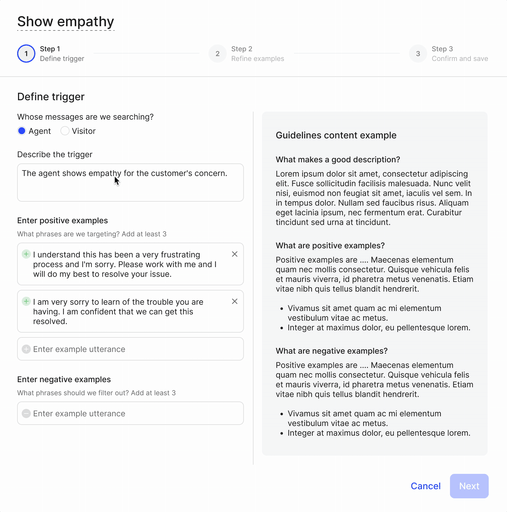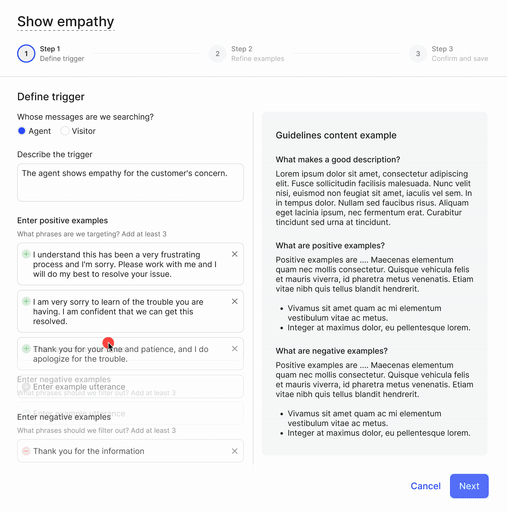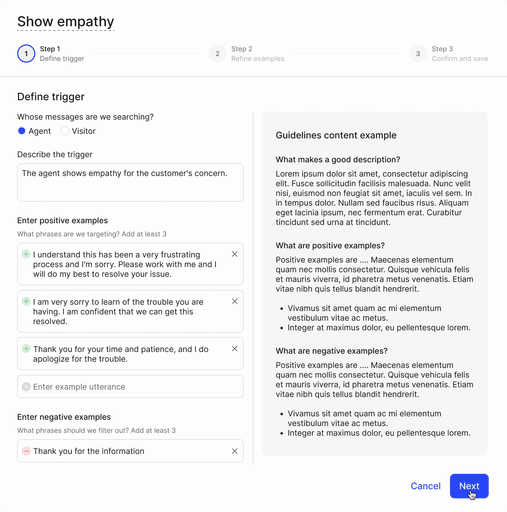


Two main feedback on the first iteration:
Too much technical jargon
Simplicity causing uncertainty
1. Too much technical jargon
Some of the terms we used internally felt unfamiliar to end users. Things didn't feel friendly and users felt "unqualified" to use the tool.

2. Simplicity causing uncertainty
Condensing the process into just three steps felt reductive to both end-users and the ML team. Users doubted whether such simplification could maintain quality standards, while ML Engineers and Researchers wanted to cultivate deeper understanding rather than oversimplifying.


Final Design
Solution 1: No need to speak the "AI lingo"
In the final design, we tried to keep the language and tone as natural as possible. No more "positive" or "negative" examples.
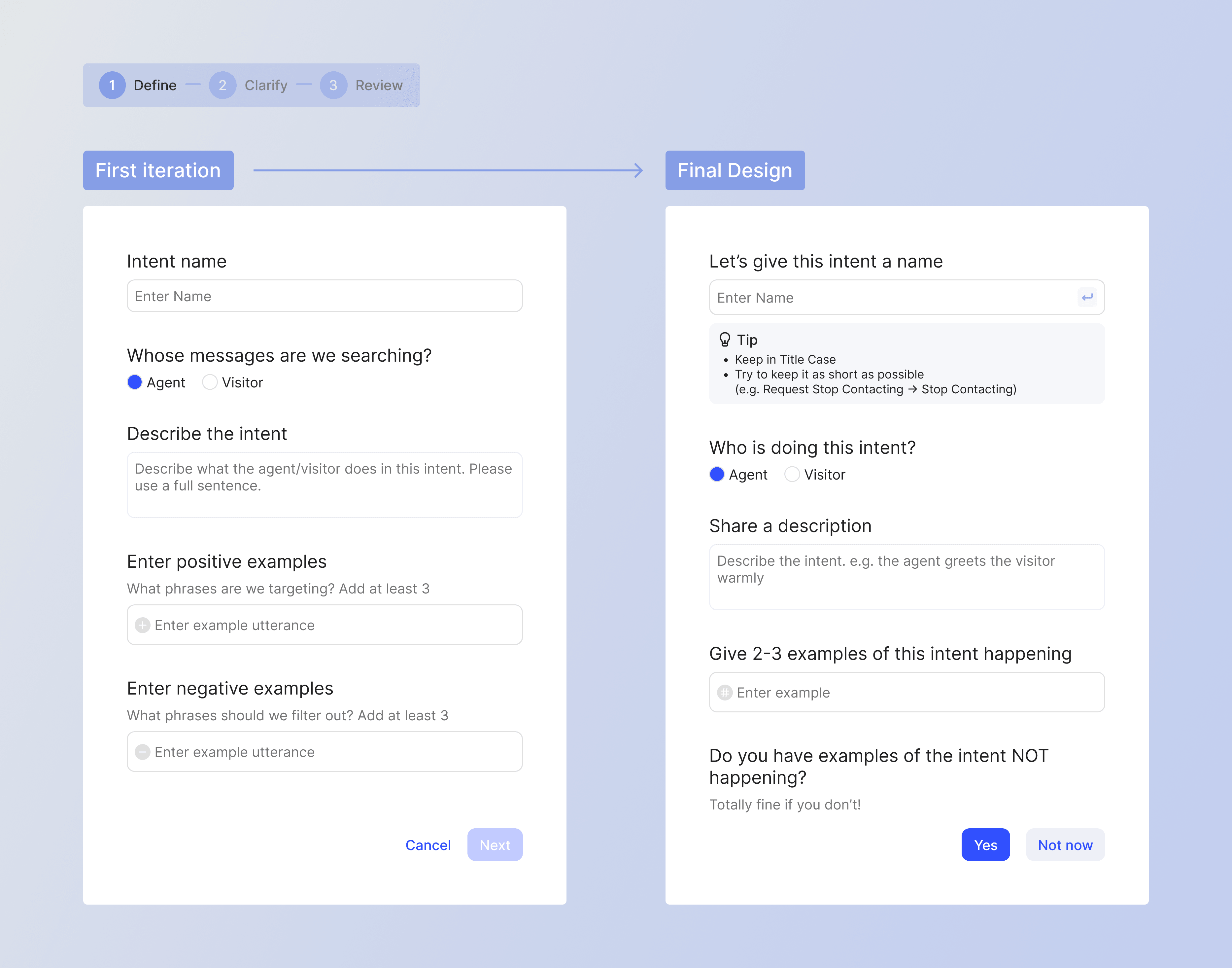
Solution 2: Longer but more robust model building flow
One big learning from the first iteration feedback was that our users preferred spending more time and fine-tuning the model. It perhaps became clearer to the users as well that this was something that had to be more than in the blink of an eye.

This insight led to many changes in how users move through the clarify phase of modeling. One change was showing a tiered rounds of examples, instead of one flat list.
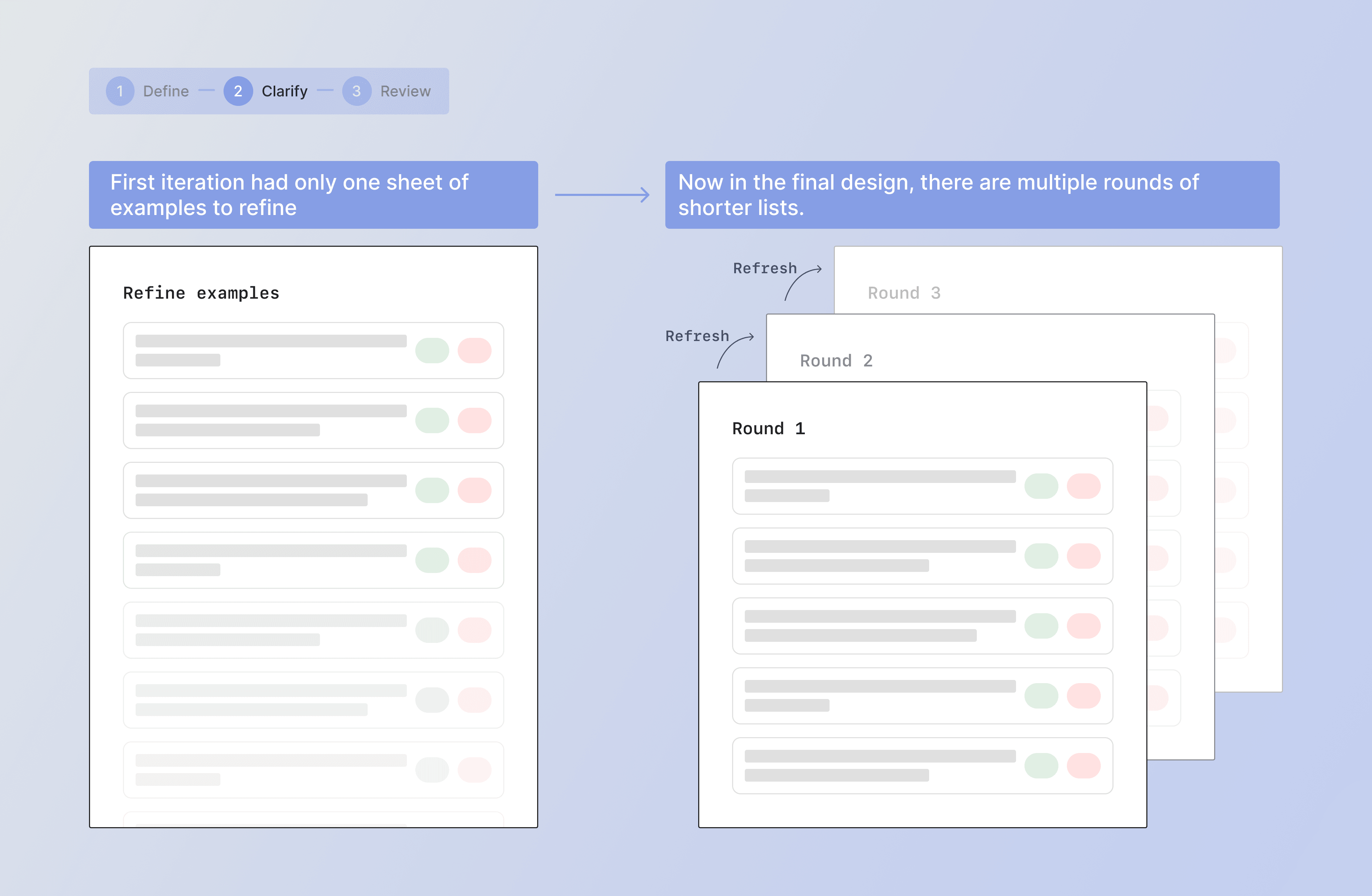
In the first round, we show the examples that the AI model is more confident about. These would be more obvious ones, the easy ones. The goal in this round is to get users' confirmation.
Then, in the second and third rounds, we'll have more nuanced examples where the model is less confident about. Users' marks on these ones will teach the model how to interpret tricky scenarios.

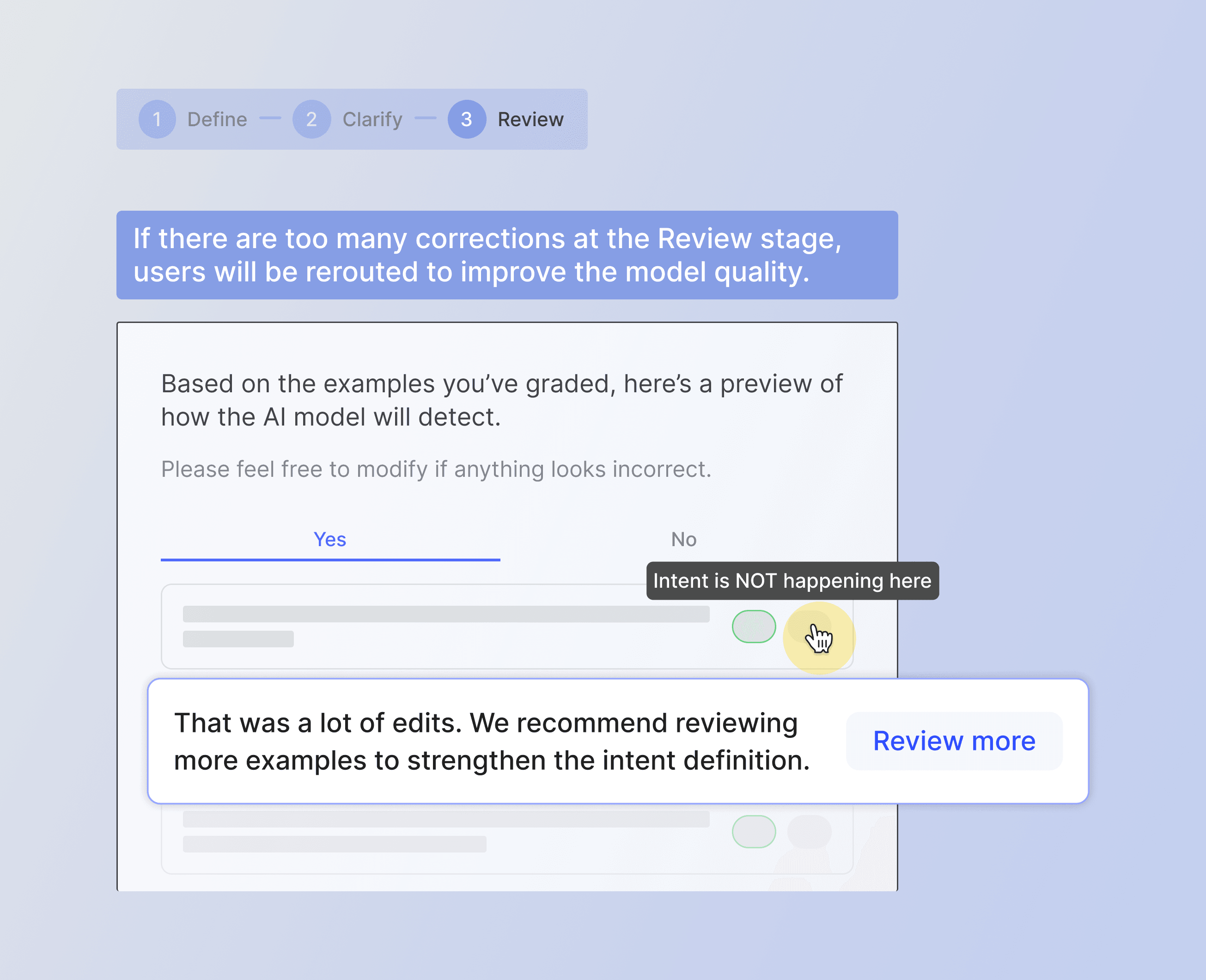
While unlikely, if users make a lot of corrections in the final step, it is evident that the model will not perform well when deployed. We encourage users to return and grade more examples to avoid this outcome.